

I'm Ariel, VP of AI at Appwrite. Over the past year, my team and I built Imagine — a vibe-coding platform that lets users build production-ready web apps using prompting. That means real backends, server-side rendering, server functions, sandboxes, previews, the whole thing.
Appwrite is one of the most impactful open-source projects in the world, and in the spirit of open-source, we want to share our learnings with the community. This article isn't a how-to. It's a collection of hard-earned lessons — the kind you only learn after shipping, breaking things, and paying real infrastructure bills.
1. Prompt caching should be a priority from day zero
If you don't take prompt caching seriously from day one, you will burn money and time. This is especially true for vibe-coding platforms.
Vibe coding platforms naturally rely on long-running agentic loops. Agents talk to themselves, call tools, revise plans, generate files, run tests — sometimes over dozens of steps and millions of tokens. That's unavoidable if you want high-quality results.
The good news: with correct prompt caching, this doesn't have to be expensive or slow.
Design your prompts for cacheability
How you structure and order your prompts has a massive impact on cache hit rates. In practice, almost everything should be cacheable.
We're huge fans of Anthropic, and they allow you to define explicit cache breakpoints. For example:
First breakpoint: after fully static system messages. Core instructions, rules, policies — things that never change.
Second breakpoint: after semi-dynamic system messages. Generation number, project metadata, decisions made by earlier agents.
Final breakpoint: right before the latest user or agent message.
This structure allows long agentic loops to reuse the majority of their context even when the workflow branches or retries. If you place breakpoints carelessly, a single conditional change can invalidate your entire cache.
Aim for 90–95% cached tokens
This sounds unrealistic at first, but it's absolutely achievable.
A good benchmark is 90–95% cache hit rate on input tokens. At that point, the economics completely change:
- A generation that would normally cost ~$1 can drop to a few cents
- Cached input tokens are also faster for the model to process
- For users waiting minutes for code generation, this speedup is very noticeable
This is the difference between a platform that feels sluggish and expensive, and one that feels snappy and scalable.
Understand caching behavior inside and out
Make sure you know how to observe caching behavior. Anthropic does an excellent job here — their console shows per-request caching status and aggregated cache metrics over time. Anthropic's documentation for prompt caching is state-of-the-art and everyone should read it.
Pro tip: You might be tempted to use cheaper models for certain tasks in your workflow, thinking it would be faster or cheaper. With Anthropic for example, cache is per model, so plugging that Sonnet call at the end of your mostly-Opus workflow would result in a cache miss. Do caching right and you can leverage the best models for the job without breaking the bank.
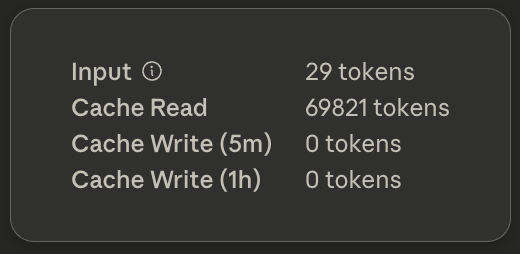 The average request we make to Anthropic is 99% cached. Screenshot taken from Anthropic's console.
The average request we make to Anthropic is 99% cached. Screenshot taken from Anthropic's console.
2. Architect for the real world, not for tutorials
Most frameworks and SDKs teach you the same thing:
Send a request, get a response, stream tokens back to the client.
That's fine for demos. It completely breaks down for vibe coding.
In a real platform:
- Agentic workflows take time
- Networks face issues
- Browsers refresh or close
- Users open the same project in multiple tabs
- Partial work must not leave the system in a corrupted state
In a vibe coding platform where state is fragile (sandbox, repo, uncommitted changes, ongoing generation, etc.), so much could go wrong.
To deal with these issues, we have implemented resumable streams and durable workflows.
Resumable Streams
Assume you have a /api/chat endpoint where the client submits a prompt. Typically, tutorials would teach you to stream the chunks back to the client (for example, using Server-Sent events, or SSE in short).
That's simply putting too much hope in HTTP connections in a scenario where generations can take minutes to complete. Here is a good approach to dealing with this:
- Client submits prompt via a
POST /api/chatendpoint. The backend performs some basic validation and triggers the generation. Client gets 200 OK response. - As the generation progresses, the backend emits stream chunks to an intermediate high-performance store (e.g. Redis).
- Instead of reading the chunks from the submit response, the client sends a follow-up
GET /api/streamrequest, to which the backend responds with all chunks so far chunks, plus all new chunks in an SSE stream. - If the connection drops, the client reconnects and resumes the stream. No progress is lost.
In our case, we serve the stream via a separate service altogether to reduce load on our core AI API, but that's not strictly necessary. Redis becomes the source of truth for in-progress generations.
Durable Execution
Streaming alone isn't enough. You also need durable execution for the workflow itself.
Instead of one long-running function, break the process into orchestrated steps:
- Each step is retriable
- Each step is idempotent where needed
- Each step has explicit, serializable input and output
This unlocks a lot of power:
- Idempotency: retries don't duplicate side effects
- Concurrency control: limit how many times a user can trigger the same action
- Multiple entry points: different triggers can safely converge on the same workflow
- Observability: you can see every step, retry, and failure
Sandbox provisioning is a good example. In our platform, there are multiple ways a sandbox might be started:
- User opens a project
- User submits a prompt
- User visits their sandbox's preview URL
With durable workflows, all of these can safely funnel into the same sandbox orchestration logic without race conditions or duplication.
We chose to use Inngest which is open-source, but there are other good options like Temporal, AWS Lambda Durable Functions, Trigger.dev, etc.
As a bonus point, using Inngest gives us great observability, overview of execution times and alerts on anomalies. It forces us to adopt a more resilient and reliable approach to building our platform, and everybody gets to sleep better at night.
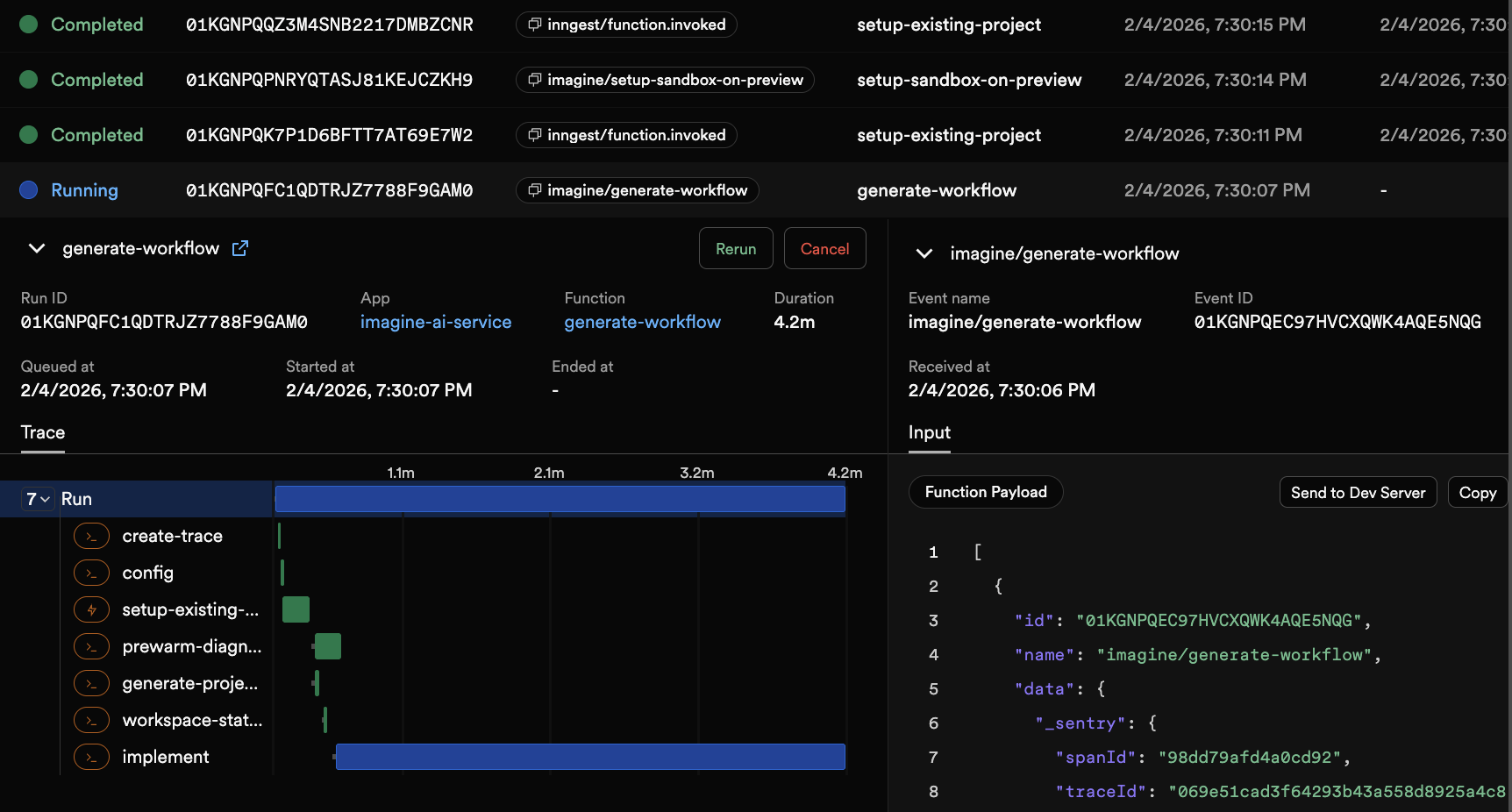
Inngest makes it easy to visualize the timeline of each generation and its steps.
3. Choose the right framework for your generated apps
When building a vibe-coding platform, you have a fundamental choice:
Do I let the system generate anything, or do I force generations to use a specific framework or stack?
We decided to go with the second approach.
When evaluating frameworks, we asked ourselves these questions:
- Does it support Server-Side Rendering (SSR)?
- Does it support server functions?
- Does it provide end-to-end type-safety?
- Can we customize the build system?
- Are LLMs knowledgeable about it?
After evaluating a few common options, we ultimately chose TanStack Start. It's built by the team behind some of the most popular tools and libraries powering the React ecosystem. TanStack Start uses Vite as its build system, which is highly customizable.
For our generated apps' runtime, we chose Bun. It's incredibly fast, supports running TypeScript directly (handy for migrations), and is pretty much a drop-in replacement for Node.js.
Concretely, we are able to build our generated apps (server and client code) in ~1 second. For comparison, a fresh Next.js + Turbopack + Bun build takes a few seconds, and that's without any server code. The difference is huge.
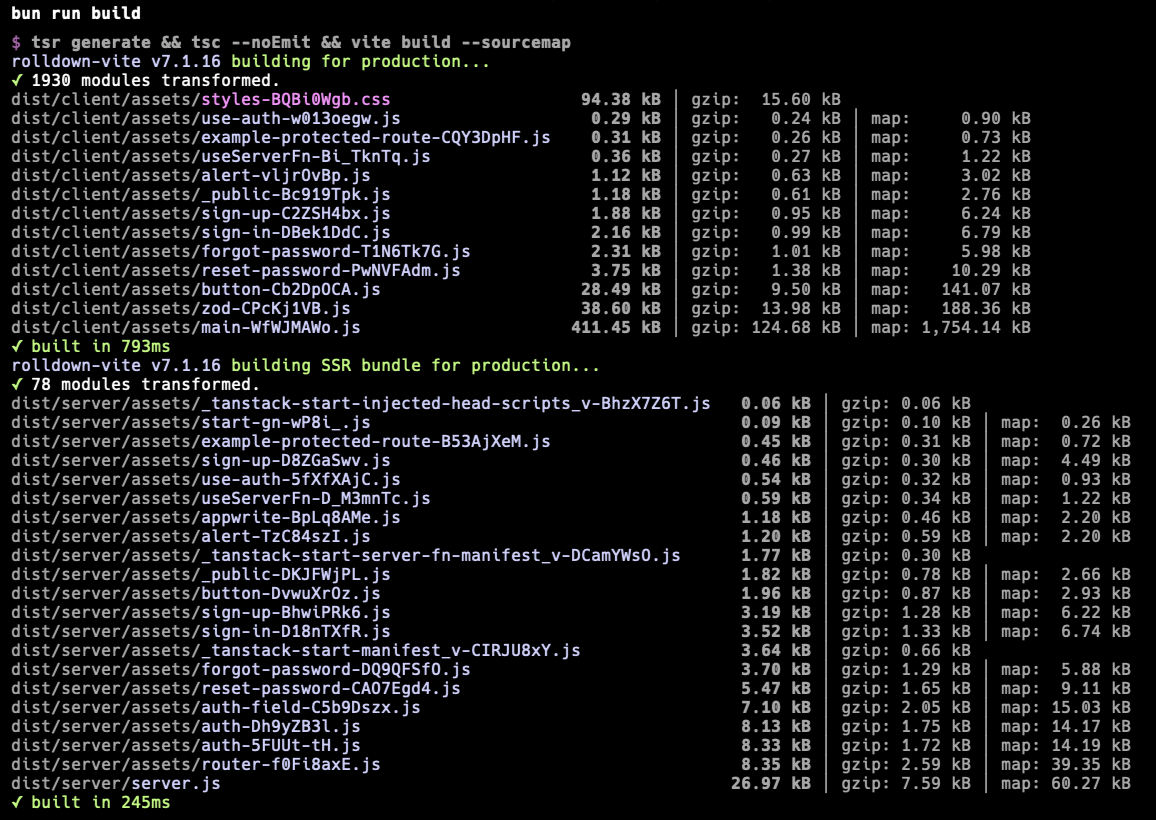 Imagine's generated apps build in ~1 second, including both client and server code
Imagine's generated apps build in ~1 second, including both client and server code
4. Embrace anything deterministic like your life depends on it
Generative AI is inherently non-deterministic. You can prompt all you want, provide examples, two-shot it, five-shot it. But as your message history grows, your context grows as well, and so does the likelihood of facing hallucinations or simply failing to get the model to adhere to your instructions.
When users report issues, 90% of those have to do with unexpected AI behavior or issues in the generated code. It's very tempting to take every such issue in isolation and try to fix it by adding an additional bullet point to the system prompt, or providing more examples.
But wait. There might be a better way. The deterministic way. Here are some examples from Imagine:
- Build the project after each generation: instead of running a traditional devserver, we decided to just rebuild the app after each generation. This gives us a lot more confidence that the code runs properly, and minimizes runtime issues. Thanks to our ~1 second build times, the overhead is pretty much non-existent.
- Embrace the LSP: our sandbox base image has a Language Server Protocol (LSP) server baked-in. We prewarm it at startup to cache the TypeScript and ESLint state, and any file change triggers a diagnostics check. Our coding agent can take up to 20 steps (distinct LLM calls) to write code, and between each step, we inject the diagnostics state into the prompt. This way, the LLM is always aware of those red squiggly lines as it writes code.
- Linting rules: there may be multiple ways to achieve something when writing code. Over time, we learned that there are better and worse ways to do things. We've found custom linting rules to be extremely helpful to enforce good practices. They are easy to write with the help of LLMs, and provide a deterministic way to enforce our standards.
- Proactively provide context: we instrument our preview iframe which enables us to automatically inject network errors, stack traces and error logs into the next prompt (including server logs). This way, we do not rely on the user to tell the LLM that something is wrong, and we also don't rely on the LLM to call tools to fetch this information. If there's an error, the LLM sees it.
These are just a few examples, but the key takeaway is that you can't rely on the LLM to adhere to your instructions. Whenever you can, embrace determinism.
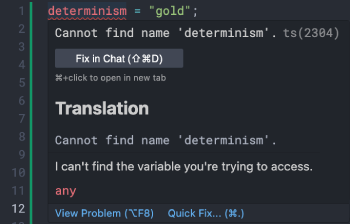 Let your AI see the same red squiggly lines you appreciate so much.
Let your AI see the same red squiggly lines you appreciate so much.
Closing words
The real challenges only show up once you're dealing with real workloads, real users, and real infrastructure bills. By then, it's often too late to "just refactor" your way out of architectural decisions made early on.
Prompt caching, durable workflows, deterministic guardrails, and a well-chosen framework should not be an afterthought, or by-the-way optimizations. They are foundational.
At Imagine, our mission is to tame AI, make the best of it and mitigate its weaknesses. We build Imagine assuming things will fail, disconnect, retry, and resume — unexpectedly.
As we build Imagine, we are constantly learning, and we are excited to share our learnings with the community. If you're building something similar, we hope these hard-earned lessons help you move quickly and avoid the pitfalls.